大家好,我是逆水,今天我们来学习一下什么叫做自身细分。首先来看一下我们曾经渲染过的图像,这个图像是用BF算法算出来的,感觉用BF算法有些浪费资源。为什么呢?可以看一下图中相框里面这一部分,各处亮度大概都差不多。但是我们知道BF算法是对每一个像素点都投射光线,所以对于相框而言并没有太多的明暗变化。每个像素点都投射一条光线很明显会浪费资源。BF算法虽然渲染效果好但是渲染所用的时间特别长,很多没有意义的点也进行了运算。
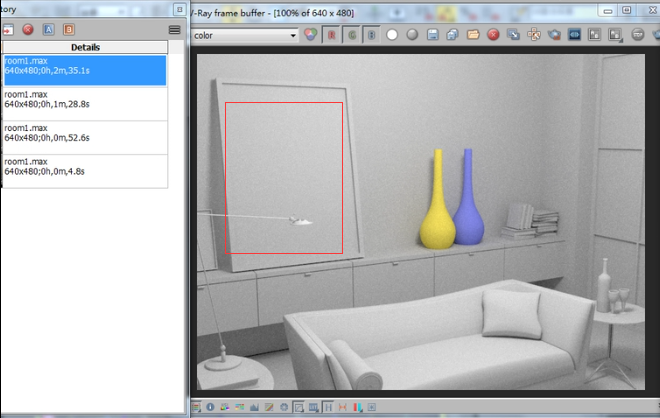
同时你会发现这幅图中似乎有一些杂点。这是因为细分值是8,明显很低。也就是说每个点分裂出的光线只有64条,导致每个点的运算不是非常准确,所以会出现杂点。如果想要运算准确,这个细分值就要提高,提高的话时间就会更长。
所以这时就出现了一个新的想法。比如有一面墙,在图像里的它表现了100个像素点,那也就是说要运算很多个点才能完成。由于这面墙的明暗关系变化非常小,那可以如何进行运算呢?
我们原来的运算是这样的:图中有很多点都是用BF算法一个一个地进行运算,很浪费时间。现在这种方法是:首先只运算下面两个点的亮度,第一个的亮度为5,最后面的那个点的亮度是20。这样的话V Ray只需要运算这两个点就可以,中间的亮度利用差值就可以得出。
例如中间的点的亮度依次分别是7、9、12、15、18.中间的这些点就不用仔细地用光线进行运算了。就是说利用两位已经运算出结果的点,模糊的在中间加入插值就可以。这种算法很明显的提高了效率。

但是有一个问题,我们看一下图,比如这是一面墙,墙中间有个茶壶。茶壶都知道它的明暗关系变化是很明显的,因为它是曲面不是平面。如果我们仍以上面的阶梯方法对茶壶进行运算的话,距离比较远,茶壶的明暗关系无法表现出来。所以对于茶壶而言,我们就得使用比较近的间距,每隔一个间距就要算一个点,而不能像这面墙一样,离很远的间距算两个点。如果以比较远的距离算两个点,茶壶的细节体现不出来。
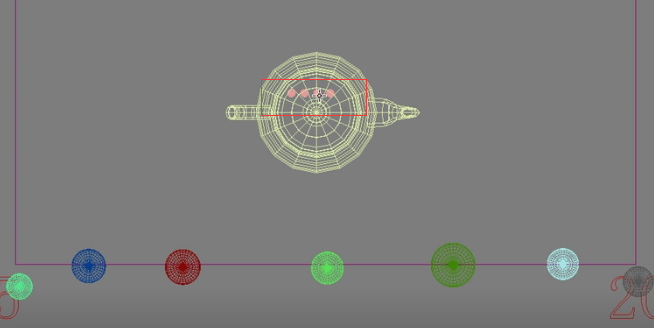
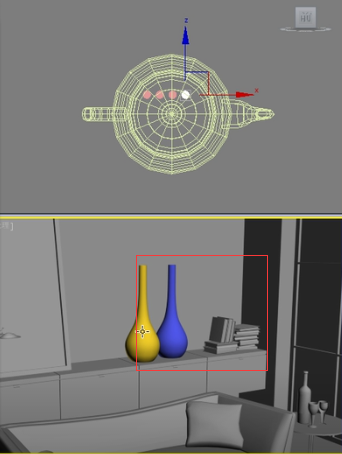
所以对于场景中的这种物体,比如下图中的渲染图。对于相框而言,以左、右框架同一水平线上的两个点,中间能用插值模糊过来。但是像旁边花瓶或者书,用大间距的两个点进行运算很显然细节表现不出来。所以这些地方就使用更加细密的点进行运算,这种方法叫做自适应细分。就是自动判断哪些地方应该密集采点,哪些地方应该稀疏采点,这就叫做自适应细分,很明显这种方法将会极大地提高速度。
那么来看一下落实到V Ray上是什么样的呢?二次引擎首先改为无,然后将首次算法改为发光图。发光图引擎是这四个引擎里唯一的一个自适应细分的方法。更准确地说它是一个完完全全的自细分算法,而光子图是一种伪自细分算法。所以首次引擎使用发光图,在这里打开它的面板,可以看到它的参数是比较多的,要比的BF复杂得多。
然后我们来进行渲染,看一下效果和时间。
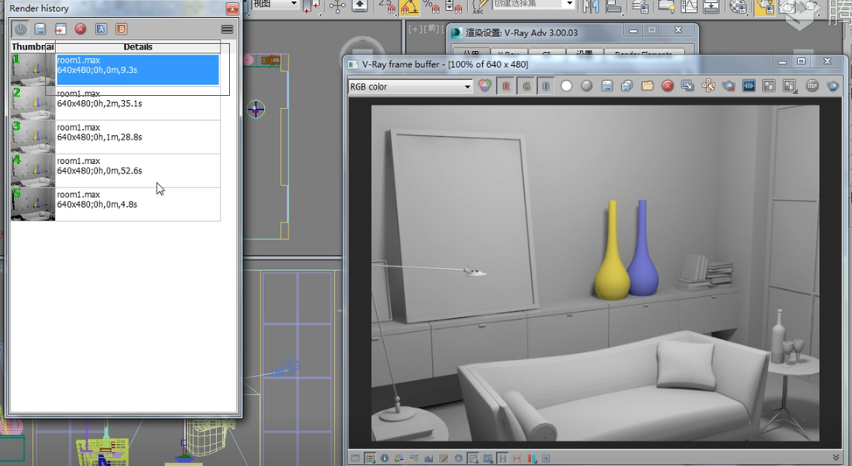
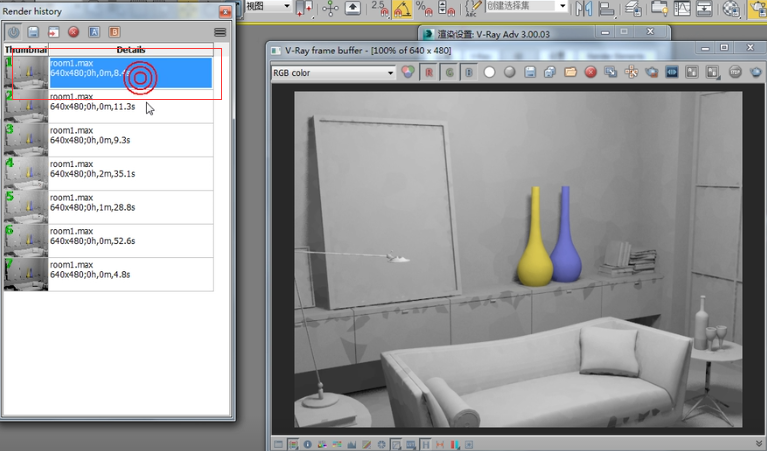
我们可以看到这个效果,做一个对比,都是640×480的。时间只用了9秒钟。然后我们对比一下之前用BF算法,是2分35秒。他们的区别在于使用发光图很明显没有BF算法那么准确,因为场景变得比较暗。但是你会注意到它的渲染时间特别短,同时这个效果也非常好。这时会给你一个错觉:发光图渲染的效果要更好一些,因为他没有杂点。在这里提醒大家不能这样理解。
发光图它是自身细分,也就是说它并不是每个像素点都采用,而是选择性的在某些地方计算一个点,而中间用插值做平滑,所以它的效果肯定是很平滑的。但是这样做的话会丢失大量的细节,很多细节地方无法准确表现出来。所以视觉上看没有杂点感觉很好,但你千万不要以为发光图的效果要优BF,这是不对的。
可以毫无疑问的告诉大家,这里边最好的算法就是BF算法。可是由于他的缺点;有些时候一张图渲染的时间太长了,在实际工作中应用的并不高。所以真正实际应用的还是发光图。因为发光图只要你正确的处理好这个参数,效果不会比BF差多少。
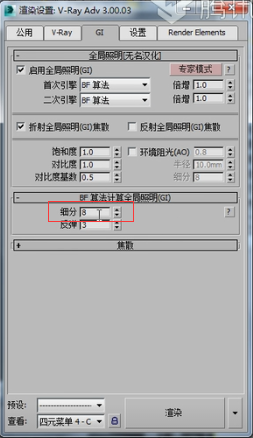
在发光图的参数里面,我们可以看到有几个模式,比如基本模式、高级模式、专家模式。事实上在每个选项面板里都有。比如在全局照明这儿也有基本模式、高级模式和专家模式。
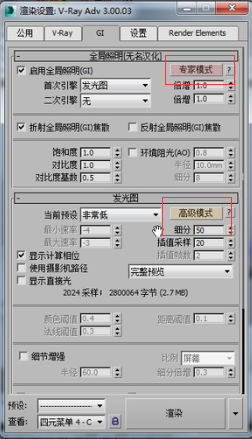
我们在发光图的专家模式下,看一下有一个当前预设,这里有一些设定好了的参数。你可以直接选择低质量、中质量、高质量等等。如果你选择自定义的话,这些参数都可以调整。
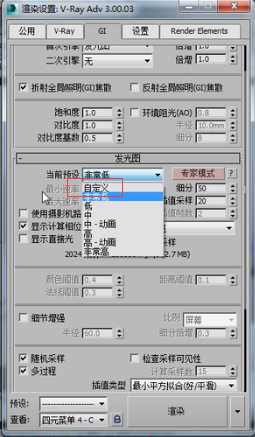
比如选择自定义,可以看到最小速率、最大速率,这些都可以进行调整的。最小速率代表的是稀疏的地方有多稀疏。比如说从渲染的这幅图片来看,相框的地方采样点应该稀疏一点,而花瓶这个地方的采样点应该多一点。那么这个稀疏的地方到底有多稀疏呢?最小速率告诉我们是-4.回头我们再解释-4、-3是什么意思,现在我们就先把它当成一个值来看。
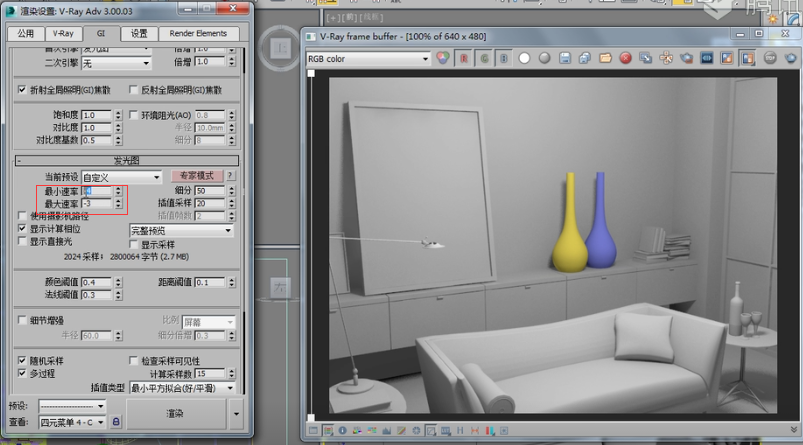
最密集的地方至多也就是-3的密集,不会更密集了。所以这个最小速率就是代表最稀少的地方有多稀疏,最大速率代表密集的地方有多密集。那很显然其他地方就会在这两个值之间自动地进行一个分配。
那么现在我们把最大速率改成-2,最小速率改成-5.这将导致稀疏的地方更加稀疏;密集的地方采样点的间距更小。那么至于它如何判断何处稀疏何处密集,我们也在随后的文章中进行讲解。现在我先给大家看一下,既然BF算法是每个像素点都投射一条光线进行运算,那么发光图算法到底运算了多少个点呢?
比如现在如果选择BF,它一共运算多少个点呢?是640×480。
而如果使用发光图算法,他运算多少个呢?我们在这儿点一下显示采样,注意要在专家模式下,有些模式下这个参数不存在。点击显示采样会在渲染中显示出来到底哪个地方采点了。我们渲染看一下,显示采样的目的就是让你直观的看到哪些地方比较密集、哪些地方比较稀疏。

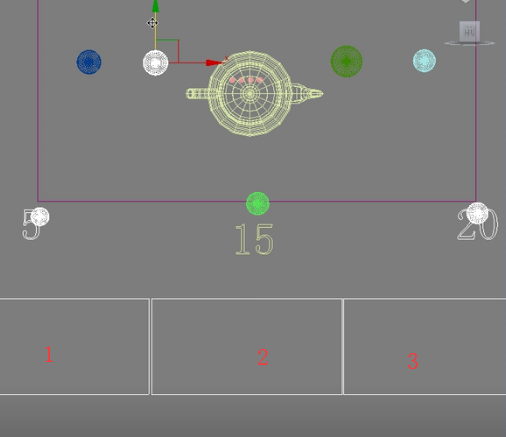
最稀疏的地方是-5这么稀疏,最密集的地方是-2这么密集。这就是什么叫做自身细分,只要谈到自身细分肯定有个最小值和最大值。那么到底采了多少个点呢?在这儿可以看到,有4183点被采了下来。相比使用BF算法30多万个采样点,这个发光图算法非常吗,至少它节省了大量时间。那么现在是4183个,现在将最小速率改成-4,最大速率改成-1.这就是说稀疏的地方也没有那么稀疏了,密集的地方更密集了。再次渲染会产生个9515个采样点。这就叫做自适应细分。

我们在这儿可以看到插值采样为20,注意这个参数叫做插值采样。
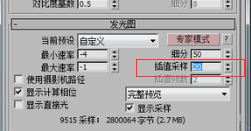
看一下我们刚才的图解:也就是第一个点亮度为5,第二点亮度为20的时候,中间加一个采样点(绿色的),它的亮度值大约是15,第二个方框区域的亮度都为15,第三个方框区域的亮度都是20,二第一个方框内的亮度都是5,所以会产生块状感。
假如在这儿加入了三个采样,采样数值为3.那么很明显亮度框就变多了,块状感也就消失了。所以这个差值采样到底有何意义呢?大家应该能理解了,他它对于速度的影响不是很大,因为算这个差值非常快的,所以这个值提高或降低不会对渲染速度产生太大的影响。但是我们可以对比一下它的效果。这张图不显示采样。

接下来我们将插值采样改为1,非常的小,再次渲染一下,对比有什么不同。时间略微降低了一些,但是注意,这个图片出现了非常明显的块状感,特别是墙壁这个地方可以看到它形成了一块一块的感觉,就是因为差值太少了,所以它产生块状感。
很明显差值越多渲染效果就更加平滑,但要注意不要单纯地用插值来找。
假如最大速率改成-10,最小速率改成-5,这样采的点会非常少,然后把差值调大一点,纯粹的用插值来找,这样的话会使这个图片的细节丢失。事实上在渲染一些效果非常复杂、要求细节表现特别多图的时候,通常还是需要使用BF算法,因为毕竟它是每点采样的。发光图可以说是一种偷懒的方式。以上就叫做自身细分原理,也是发光图这个引擎最根本的一个原理。
那么今天就给大家分享到这里,如果你觉得文章对你有帮助,希望将网站分享给你的朋友。感谢大家支持!






请先 !