大家好,我是逆水。今天我们来学习灯光缓存细分与块结构。
首先我们来讨论一下细分值的作用。细分值指的是从摄像机发出多少搜寻的光线。也就是说从摄像机发出搜寻光线的数量。这个值他的平方就是实际的数量,比如五百,就是二十五万,代表的从摄像机发出二十五万条搜寻光线。
那么这会有一个问题,我们的采样大小是0.02,比例是屏幕,
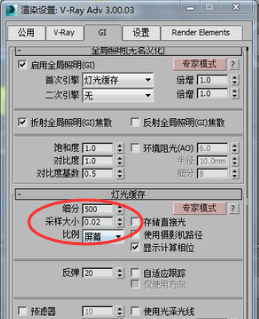
也就是说我们横向有50个块,纵向也有50个块。总共是2500个块,2500个块需要25万条光线进行运算。这就是用来确定一个块的准确程度。
我们举例说明一下,比如这是其中的一个块,

其中一条搜寻光线照射到这里,
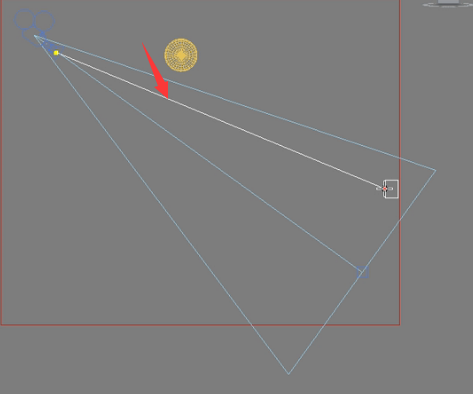
然后反向运算出屋顶对它有光线,反弹,之后反弹多少次,由这个反弹次数来决定,最终我们反弹到灯光。
我们假设他就反弹一次,因为反弹多次肯定运算就更加准确了。
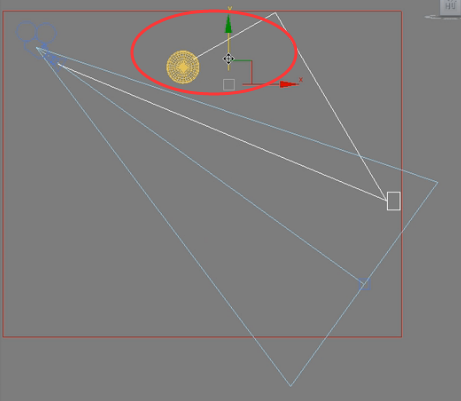
运算灯光得到结论,这条光线的亮度是10。也就是说这个块的亮度是10。因为我们从之前的文章知道灯光缓存的这个块,也很清楚了,他这一块亮度肯定是不会再变了,这一块的亮度是相同的。
但是这样的计算肯定不是准确的。为什么呢?
如果又有一条光线也照射到这个位置,
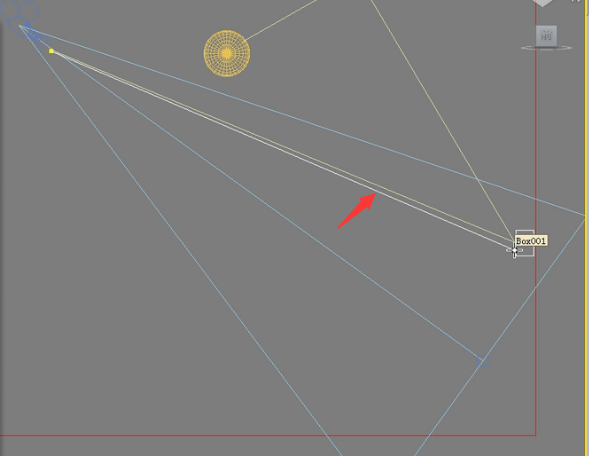
然后运算出地面对它也有反弹,
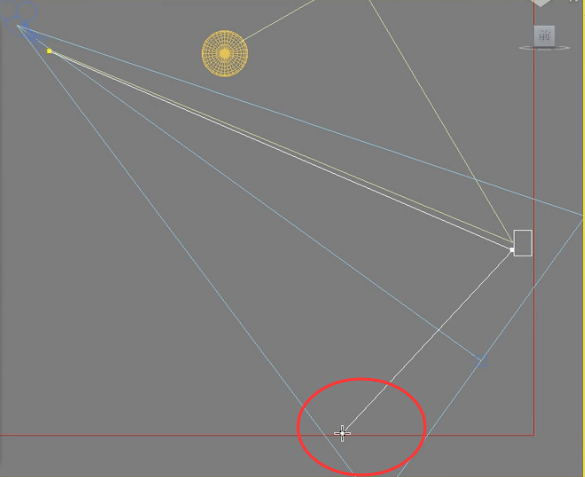
最后得到结论这个块的亮度应该是6。
那么最终这个亮度是多少呢?那就是第一条算的是10,第二条光线算的是6,那么就是10+6然后再除以2,最后得出这个平均值,得出这个亮度是8。
很显然如果只有一条光线,算的肯定不准确。那么两条光线就相对准确一些。
那么假如有三条光线呢?比如对面墙,也有能量反射过来,
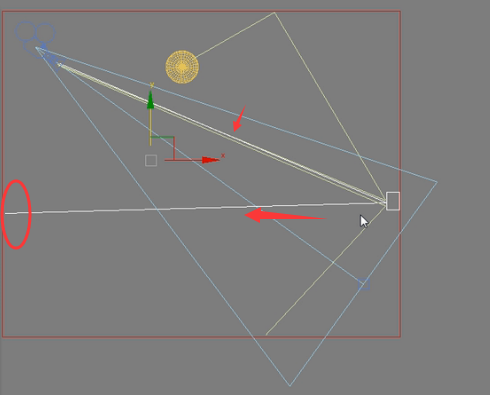
很显然算的就会更加准确。可想而知我们灯光缓存这个细分值,发射出的搜寻光线越多。那么每个块最终的亮度将会算的更加准确。这就是细分值的作用。
那么500这个值低了一点,一般这个值默认的是1000,
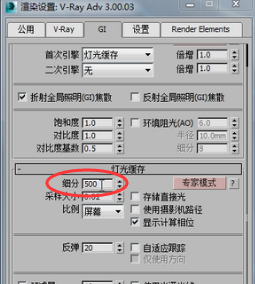
那么1000个人感觉稍微有点高。特别是当灯光缓存用于二次引擎的时候。
事实上作为二次引擎的时候这个细分值就不要调的太高。
那么现在我们先来看一下灯光缓存的块结构。我们先用这个值反弹20次渲染一下,然后我们用光子贴图查看器,看一下他的块结构。

注意我们的这个插值还是没有加,保存一下,灯光缓存可以和发光图一样,可以把光子贴图文件保存起来。
但要注意灯光缓存的这个后缀名是vrlmap,多了一个l。代表这是灯光缓存的光子贴图文件。文件保存。
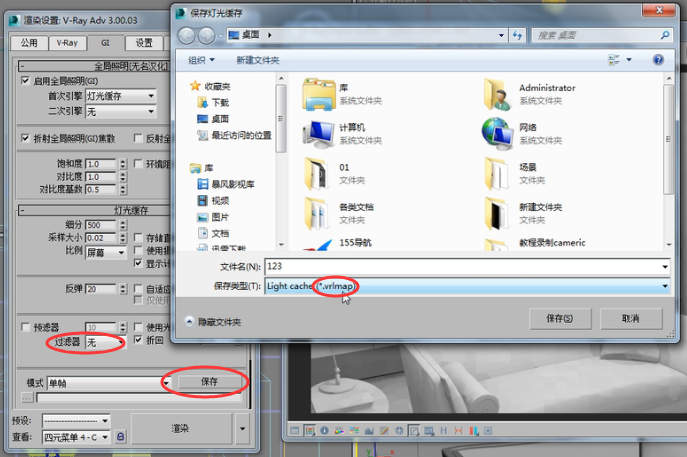
我们利用光子贴图查看器查看一下。
首先我们可以看到摄像机所观察到的地方是按照标准的我们指定的这个块大小进行排列的。
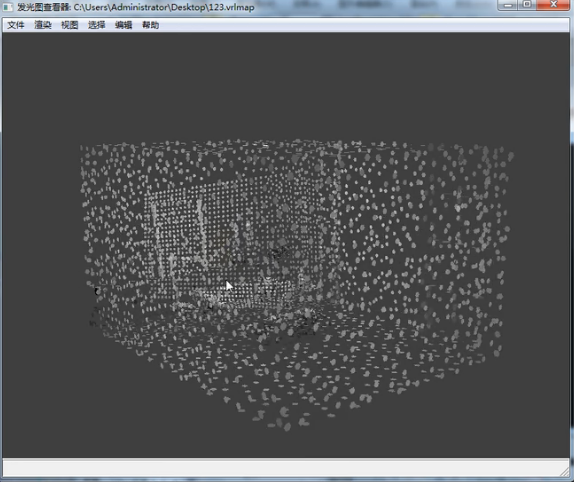
那么我们这里有个疑问,比如发光图只有摄像机看得到的地方他才会记载每个采样点的亮度,看不到的地方他是不记载的。
但是灯光缓存不同,我们曾经说过无论灯光缓存用于首次引擎还是二次引擎,他的运算过程都是一模一样的。
那么很显然作为首次引擎,他没有必要把这些地方的采样点的亮度都记载下来。
可是如果作为二次引擎则不同了。比如我们的首次引擎是发光图,二次引擎是灯光缓存,
那我们知道发光图是这样运算的,
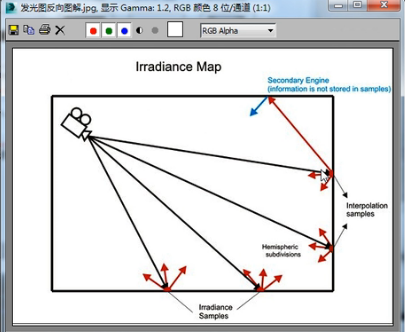
首先发射出搜寻光线,然后进行自身细分,然后判断各点的亮度是多少,之后是二级反弹,二级反弹需要运算这个点的间接照明,或者是反弹之后其他点的间接照明。
我们可以看到灯光缓存已经把其他地方,包括摄像机看不到的地方,每个块亮度是多少都已经计算完毕了。
所以他作为二级引擎的时候,他保留这个结构就是为了给首次引擎提供这个数据。
但是你可能会想,灯光缓存作为首次引擎他可能没必要记载。这是灯光缓存的特点,他用于首次或者二次他的运算过程是不变的。
回到我们刚才的话题上,我们可以看到,摄像机看不到的点,这些点的疏密程度是由谁来决定的呢?

那就取决于搜寻光线照到我们摄像机所能看到的这些地方,反弹到哪里,反弹到哪里哪里就记载一个点。
为了证明这一点其实很简单,我们看当前的这个效果。
我们把灯光缓存我反弹次数改成一次。
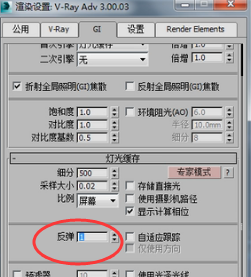
那我们再看下效果。

也进行保存,用查看器看一下结构分布,
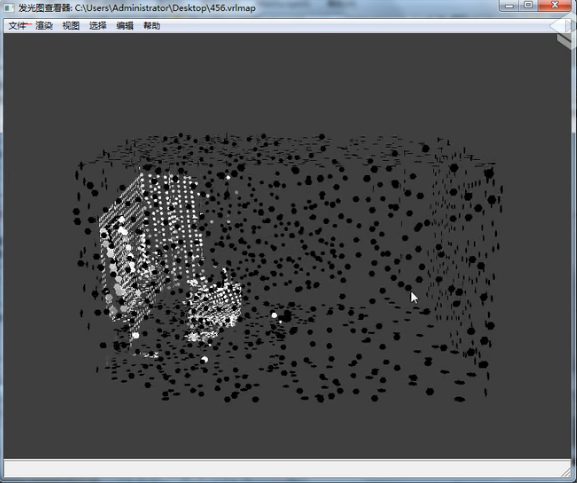
那么你可以看到很明显的,摄像机看不到的地方这些点都是黑的。就是表示这个采样点没有任何亮度,但是光线反弹到这里了。
那这个是个什么意思呢?很简单我们通过这个图解看一下,
一条搜寻光线搜寻到这个点,
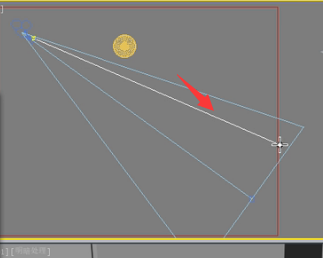
然后反弹到屋顶对它有运算,

那由于他只反弹了一次,所以他要判断这个点的亮度是多少,

判断这个点亮度的时候会发现这个点有直接照明,但他的间接照明就不再运算了,因为我们只反弹了一次。所以他会记载这个地方有采一个点,但是这个点间接照明不运算。只有直接照明。所以在光子贴图查看器里他是黑的。
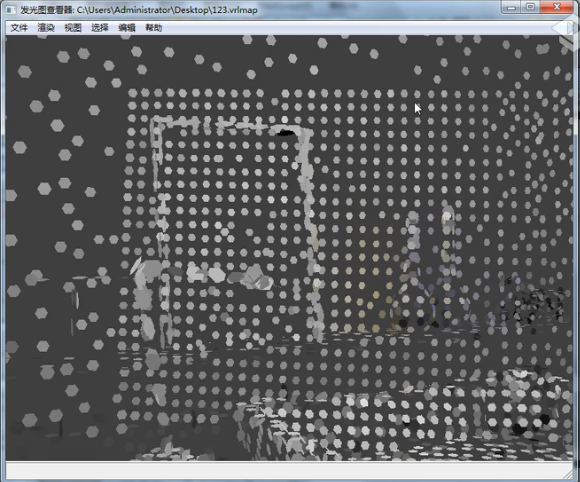
而如果我们把这个反弹次数改为2次呢?渲染一下,
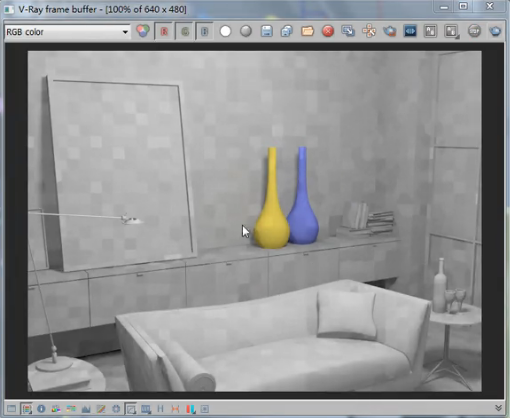
再进行保存。观察一下反弹次数为两次的光子图,
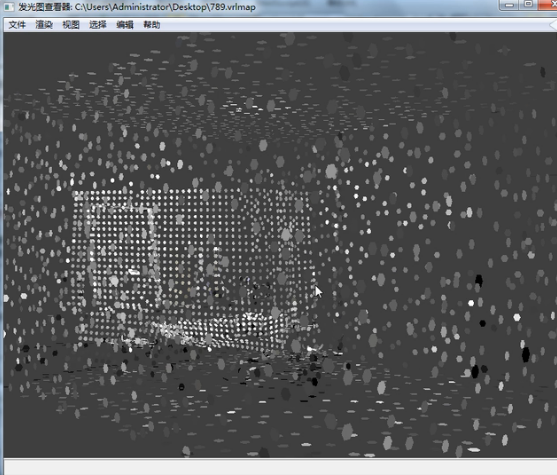
那么从这个结构就更能明白他的原理了。你会发现会有几个发黑的地方,这些地方肯定是光线反弹两次之后后面没有运算了,所以他是黑的。
那么这些亮点是什么呢?一次反弹就能反弹到的地方。
这就是为什么我们反弹两次后白色的地方变多了,但是仍然还是有几个黑点。很显然我们的反弹次数越多,黑色的点就会越少,并逐渐消失。
因为反弹次数越多,会使后来的光线,比如开始有100条光线,那它们反弹生成这些点,后来的100条光线,再次反弹碰到这些点时,由于灯光缓存的逼近式运算原理,所以他发现这个点有人运算过了,直接到这他就终止了。只有那些没有被运算的地方,他才会继续运算下去。
通过这个我们也可以看到灯光缓存的一个运算原理。
下边我们就来看一下,细分值的意义。
我们知道这个值的平方是实际投射的光线数,那么光线数越多,能把一个块算的更加的准确。但也不可盲目的把这个值调高。因为会影响他的渲染时间。
我们来看一下具体这些光线是怎么分布在这个块上的。
比如我们的光线数是32条,而我们的块是16个,那是不是每个块就有两条光线呢?不是的,这是因为灯光缓存虽然不是自身细分,但是V-Ray整体算法就有一个 全局确定性蒙特卡洛,这里有个自适应数量,
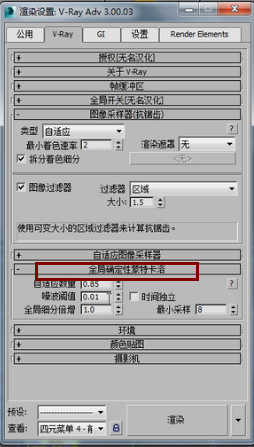
那么V-Ray事实上他的所有算法都是带一点自身细分的,那么这个自身数量呢这是一个整体设定。这个参数回头我们会详细讲解一下。
总之你要明白一个道理,就是V-Ray无论哪一个算法都有一个全局性的自身数量。所以这些光线不可能是平均的。
我们这个细分值一定要选一个比较恰当的值,什么叫恰当呢?比如我把这个细分值改成5,
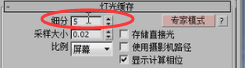
那么就出来个问题,5的平方是25。从摄像机仅投出了25条搜寻光线。而我们的块有2500个块。那么这25条光线能不能生成2500个块呢?那是不可能的,因为某些块一条光线的偶分不到。
所以这样你的块大小是0.02,根本无法形成块结构。我们可以渲染一下看一下效果,

我们可以看下这是当前的效果。很明显很多地方根本没有形成块结构。我们把他保存一下。
观察一下这是我们用0.02生成的块结构。现在仍然是0.02,可是我们看到根本就没有形成块结构。

所以这个细分值和采样大小还是有一定关系的。你得细分值至少要达到形成块结构的大小。
那也就是说我算好了正好是2500条光线,那么这个值是50,恰好50的平方是2500。这个采样大小正好也是正好形成2500个块。
那这样的话会不会形成和刚才我们看到的这样一个结构呢?这也是不可能的,因为我们说过他并不是平分的。他毕竟有一些自适应。
所以肯定还有很多块得不到光线。所以仍然无法形成一个细腻效果的块结构。
我们可以渲染一下,

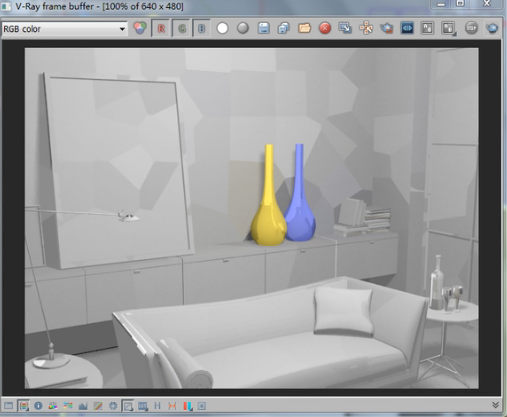
这是当前生成的一个块结构,我们可以看到这个块特别的大,而我们0.02不可能产生这么大的块,这就是因为我们很多地方根本没有获得光线。所以我们保存,然后用光子图进行观察,

你可以看到这个效果,也是没有达到我们刚才的细腻程度,没有形成完整的块结构。我试一下300的效果,

渲染一下,
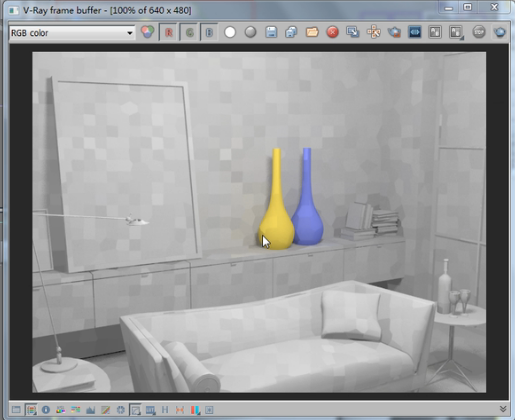
好了,大家可以看到这是300的效果,从视图中我们可以看到块结构已经表现出来了。说明这个值至少达到了能够形成块结构大小的这么一个数量。
然后我们保存一下,仍然用光子图看一下,

可以看到现在这个程度基本可以表现这个块结构的。
那如果这个值再高会表现出什么效果呢?比如我们把这个值改到1200,
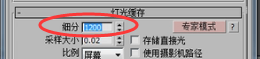
看一下效果,
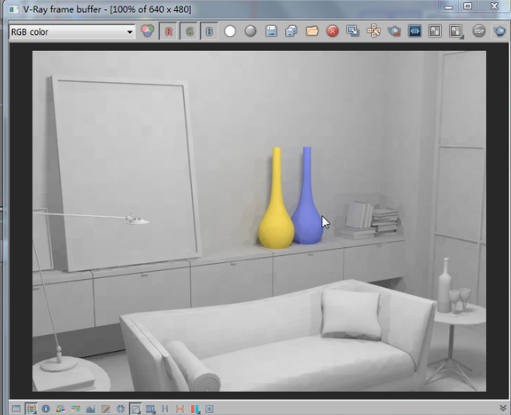
在这你可以看到这个块结构不是很明显,这是为什么呢?
因为我们的光线足够多了,每一个块都算的毕竟准确。各个块颜色相差事实上并不是很多,所以算的准确了之后,你可能会感觉块少了,不是的,块还是那么多,只不过每个块算的更加准确了。所以相邻的你就看到不大清楚了。
那我们仍然把它保存起来对比一下,

我们使用1200和使用500的摄像机所看到的位置的块结构没有任何改变。
那么就是说这个值你应该调到能够形成块结构,否则的话就无法形成块结构了。
我们假设500就能形成块结构了,我们把他调到5000,块结构也不会发生变化的。
但是两者有什么不同呢?首先每个块算的更加准确了。其次细分值500时摄像机看不到的地方的采样点比较稀疏,细分值1200时摄像机看不到的点变的密集了。这是为什么呢?因为光线数多了。所以在摄像机看不到的地方采样点变的更多。这个道理应该是很好理解的。
所以当我们能够形成块结构的时候,比如500能够形成块结构,但是我们希望他能算的更准确一点,他可以把这个值适当的调高。当然调的太高,意义就不大了。
毕竟如果作为二次引擎的话这个值1200一般来说已经足够了。当然这是基于我们当前的这个分辨率。640*480,
如果你要渲染一个超大的图,比如6400*4800,采样大小是0.02,你可以想象一下一个块有多大。因为是固定是他百分之多少的大小。这样的一个块可能会大了一点。所以我们可能会把采样块大小调小一些,那对应的细分值就会相应的提高。
好了我们这篇文章很啰嗦的方式解释了细分值具体有什么意义,以及跟采样大小的关系。
那么今天我们就给大家分享到这里,如果你觉得文章对你有帮助,希望将网站分享给你的朋友,感谢大家支持!






请先 !