大家好,我是逆水。今天我们来学习一下灯光缓存引擎的特点。这个引擎是一个非常非常好的引擎,他是一种逼近式渲染的方法。一会儿我们会解释一下什么叫逼近式渲染。
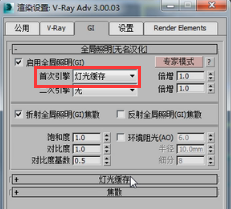
首先我们要看的就是灯光缓存的特点是什么。我们知道每个引擎他都有他的特点,比如BF算法有什么特点,发光图有什么特点,如果用一句话概括呢BF是每像素点采样,发光图最大的特点自身细分,灯光缓存最大 的特点就是块结构。
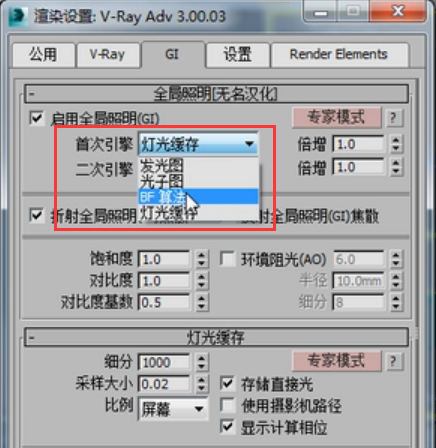
首先他会有一个采样大小,由这个大小形成块结构,然后进行运算。
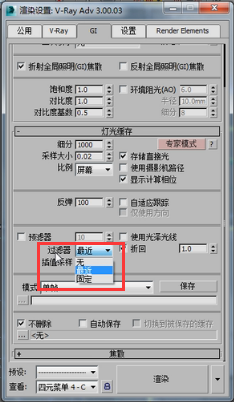
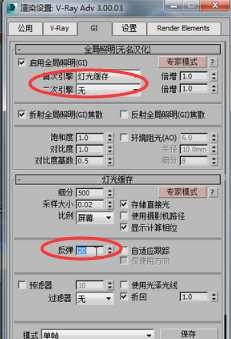
可以说灯光缓存这个设计还是不错的,他的优点就是他不像BF那样每像素点采样,也不像发光图那样进行自身细分。灯光缓存你首先你要确定的是他不是自身细分,没有自身细分这个运算。他的最根本结构就是块结构,采样大小就决定了一个块是多大。我们如何来验证这个块结构呢?首先在这呢我们注意先把他的插值采样关了。也就是过滤器这选择无。回头我们再细讲,无的话就表示不进行插值采样,他默认的是最近的进行一个插值采样,我们先选择无,让他没有插值。
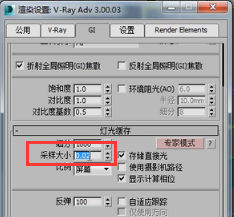
然后渲染看一下这个块结构到底是一个什么样的结构,为了渲染快一点我先把这个细分改为500,然后大小是0.02,注意他使用的单位比例是屏幕。也就是说每一块有多大呢?是你当前渲染分辨率的百分之二那么大,为一个块。

我们现在渲染一下看一下结果。好了渲染完成,
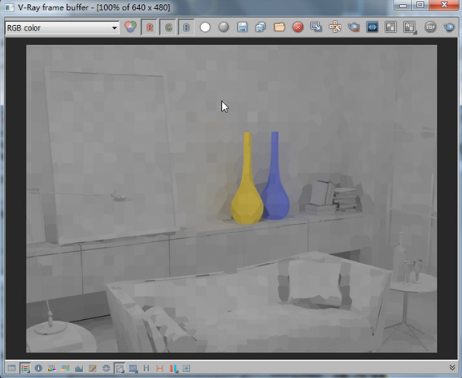
我们可以看到灯光缓存的渲染时间好像很长。看到用了一分多钟才渲染完,

我们主要要看的就是这个块,大家可以看到这个是一块一块的,那也就是说他的采样点分布很简单,他把当前这个摄像机能看到的大小拆分成一块一块的区域进行运算,比如这块区域需要多亮,另一块区域需要多亮,他把他运算出来,在这里我们对比一下发光图产生的块状效果。
我们选择发光图,

然后选择-5到-2,我们把插值采样也关掉,最小值也就是1,

我们渲染一下看发光图渲染出来块结构是什么样的,
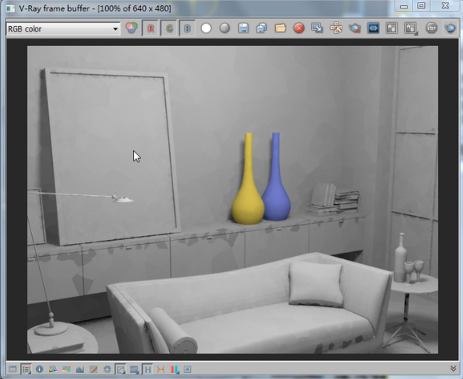
我们对比就会发现发光图生成的块结构由于有自身细分,所以他生成的效果就是有的地方块比较大,有的地方块比较小,为什么呢?因为他是自身细分,一些地方采的点多,一些地方采的点少,由于中间没有插值,做中间的模糊运算,所以他形成的也是这样一个块结构。

相比之下,灯光缓存没有自身细分,他是纯粹的进行一个阵列,就是一个排列,平均的在当前摄像机能看到的这个区域里进行一个这样的分布。这就是他的最大的一个特点是块结构。那么在这你也能更好的理解发光图的自身细分,但是这两者都需要插值来进行中间的模糊运算。这就是灯光缓存的一个特点,那如果现在我把插值打开,这个效果就不会像刚才那样出现很多块。
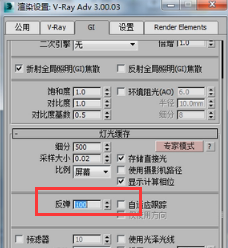
在这我们先讨论一下这个反弹是什么意思。
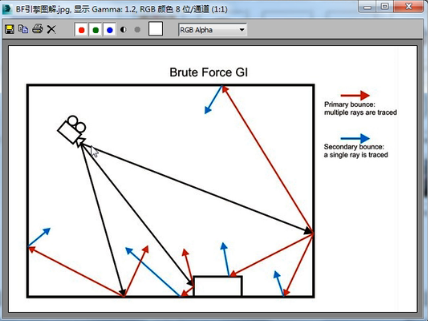
这个反弹的意思就是光线来回反弹多少次。我们先来看一下这个图,首先从摄像机发射出的搜寻光线照射到一个块上边,因为他是以一个块为单位的。
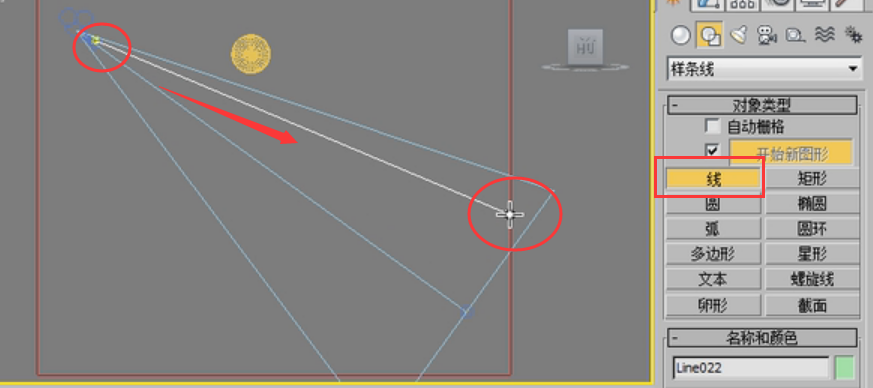
照到这个块上面,他运算这个块的亮度时会运算这个点,比如屋顶有光照下来,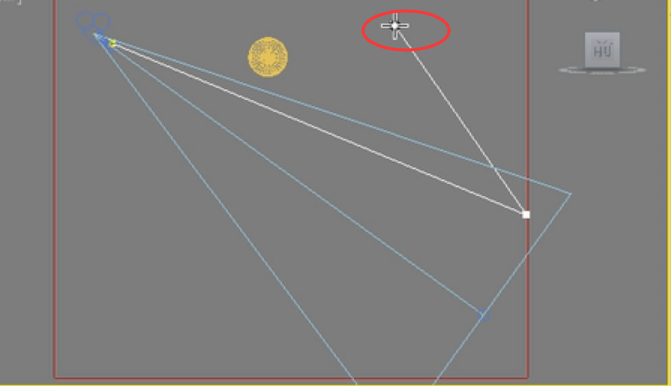
那么他运算这个点的亮度,之后这个点的间接照明运算这个点,

那么来回反弹多少次呢,来回反弹一百次。要达到一百次的反弹。大家知道BF算法默认的才三次反弹,
而我们使用灯光缓存的话,他用的是一百次反弹,按照我们的想法一百次是不是时间会特别的长呢?事实上却不是这样的。为什么呢?就因为灯光缓存他的算法也是非常独特的,他是一种逼近式算法。到底什么叫逼近式算法呢?我们看一下灯光缓存的结构图。
在这我们可以看到,摄像机发射一条蓝色光线,他的反弹次数非常多,然后我们再看红色这条,红色的代表另一条,当他跟蓝色光线反弹到一个点时,他发现蓝色光线已经计算了这个点的亮度,红色光线他就终止了,也就是不再向下进行运算了,这个就叫做逼近式的运算。
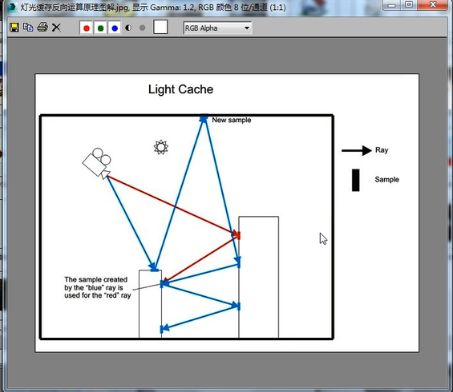
所以虽然我们在这里看到的反弹次数是一百次,但是并不代表从摄像机发射的搜寻光线每根光线都有搜寻一百次,那是不可能的。很多可能算五次,或者二十次就终止了。因为他遇到之前运算过的点时他就终止了,而使用之前的这个信息。那这就是逼近式渲染,也使得我们这个场景算过的地方不会出现重复运算,没算过的地方会接着算下去,所以这种渲染方法是一种非常非常高级的渲染方法。他能使这个渲染的效果更加逼近真实。可是即使这样,这个默认设置的100也太高了,没必要,我们把他改成20,

很显然这个值越大,他的渲染时间就越长。
那以上我们就讨论了灯光缓存最最主要的两个特点。第一个块结构,第二个就是他的逼近式运算。由于这两个特点,我们来判断一下灯光缓存他有什么好处呢?首先他并不像BF算法这样无法控制,因为BF算法只要你用他了,他就每像素点进行运算,相比之下,灯光缓存可以用这个块来决定,到底运算多大一个块。这样就仿佛是一个BF算法,可是有了一个采样大小的控制。另外如果你使用BF算法,他可没有这么高级。
比如你使用BF算法,细分值是8,

每条光线分裂出去,分成64条,这64条之后每条独立的进行运算,我们再来回忆一下我们说过的BF算法的原理。
照过去之后进行分裂,分裂之后再进行采样运算,就是单个运算了。那这个有什么不同么?BF算法他反弹到这个点他并不会判断这个点有没有运算过,有没有其他光线运算过,他只会这样直接的运算下去。他并不像灯光缓存算法这么好。所以从这可以看出灯光缓存这种引擎的优势。
另外有的同学肯定会感到疑惑,首次引擎灯光缓存,二次引擎是无,那么下边这个反弹有什么意义呢?
灯光缓存他有这样一个特点,无论他放在哪里,他的运算过程和原理都是一模一样的,也就是说你把他放在首次引擎里面还是二次引擎里边他都按同样的方式进行运算,也一直这样算下去。那你可能说这是什么意思呢?就是如果你的首次引擎使用灯光缓存,他并不在乎你的二次引擎有没有,他仍然会这样不停的反弹下去,进行运算。所以你的首次引擎使用灯光缓存,二次引擎使用哪个都没有意义。因为他已经不承认二次引擎。如何能证明呢?我们来渲染一下,
我们做一下保存,然后看一下时间,
接下来我们把二次引擎改为BF算法,我们把反弹次数多加一些,这样让他占用的时间更长一些,

注意这个细分值是无效的,大家没忘吧,BF算法用于二次引擎细分值是无效的。我们看一下渲染,

看一下渲染时间,仍然是16.4s。

有零点几秒的差别,是没有变化的,这个值不变每次渲染个七八次,都有零点几秒的差距,可见无论你选择什么二次引擎,已经无效了。然后我们再对比一下效果也是一模一样的,
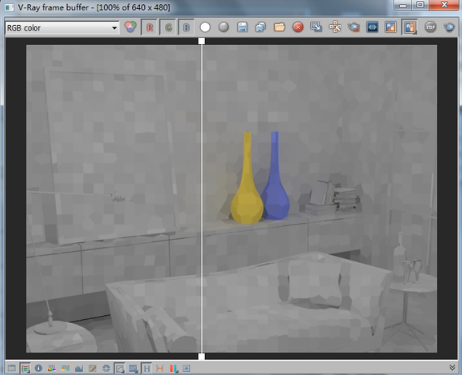
这就是灯光缓存的特点。无论他放在哪里,首次还是二次,他都是这样进行运算的,所以切记,如果你的首次引擎选择了灯光缓存,那么二次引擎你就可以考虑选择无。因为你选择任何一个都无效了。根本就不承认二次引擎。那么这些值对应来说也就没有意义了。下边我们来看一下加入插值后的效果。
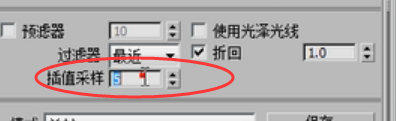
过滤器选择最近,插值采样改为20,其他值没有变,渲染一下,
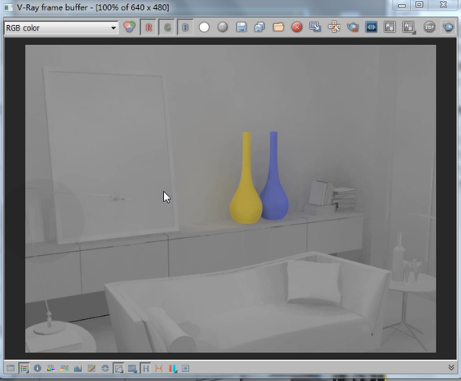
大家看这是我们加入插值以后的一个效果,当然这个效果不是最终的效果,感觉这个效果有点灰,我们关闭存储直接光,
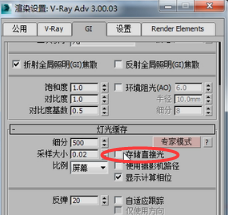
渲染一下,
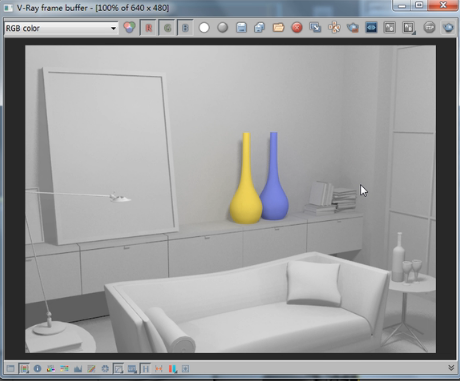
大家看现在这个渲染效果是不是好一些,那么这个存储直接光到底是什么意思呢?这个不在我们这节课的内容,回头我们会详细解说这些参数。那么我们总结一下这篇文章就是灯光缓存这个引擎的特点,如果概括一下就是三大特点,一是块结构,第二逼近式运算,第三无论是把它放在首次引擎还是二次引擎里面,他的运算过程和运算机制是完全相同的,没有任何不同。所以你首次引擎选择灯光缓存,二次引擎就立刻变得无效了。
好了今天就给大家分享到这里,如果你觉得文章对你有帮助,希望将网站分享给你的朋友。感谢大家支持!






请先 !